HDFS RAID导致NameNode out网络流量异常飙升
简记一次之前遇到的NN网络流量异常飙升的问题(NN网络流量飙升有很多中情况,如下只是一个特例)
##问题现象 Ganglia监控发现,NN的out流量异常飙升,上升到60M~80M,关闭RaidNode之后流量下降到正常水平20M左右
##问题分析 NN和RaidNode之间的数据传输主要是raid目录的文件信息查询(参见之前的HDFS RAID介绍),主要通过DirectoryTraversal遍历目标文件中每个文件信息,返回目标目录中所有符合raid条见的文件。事实上这个遍历过程需要向NN递归调用FileSystem.listStatus(),请求目录下所有文件的信息,返回是一个FileStatus列表。 FileStatus结构主要如下:
一个FileStauts除去Path之外序列化网络长度大概为140Byte,而Path的长度主要和其所对应的文件实际文件路径长度有关,云梯中一般为150Byte+的长度,也就意味这一个FileStatus的网络传输数据大概为240B,一般一个目录下有几十~几百左右的文件,一次FileSystem.listStatus调用传输的数据量大概是10k~100K,统计listStatus的RPC调用,ops大概是240,也就是该调用的每秒网络传输大概是2.4M~24M左右。貌似(注意,目前只是貌似)和NN异常流量有关。
第一阶段修复
社区中针对FileStatus中包含Path导致网络传输过大的问题,已经有一个patch进行解决,该patch主要通过一个不包含Path信息的HDFSFileStatus替换原有的FileStatus,减少Path信息的传输,参见: https://issues.apache.org/jira/browse/HDFS-946Q
验证
修复后进行验证,发现,流量却是有小幅下降,并没有起到本质的变化。
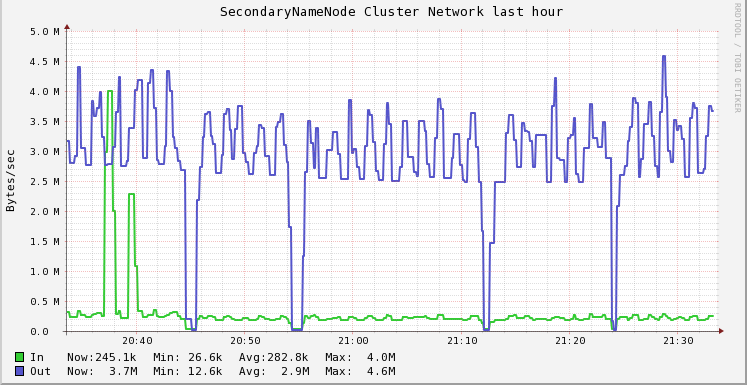
重新排查
重新观察流量情况,发现NN有显著的out流量增长,但是对应RaidNode上并没有显著的In流量增长,并且发现关闭RaidNode后,NN的out流量并不会立即下降,而当kill掉所有Raid Job后,NN流量显著下降。
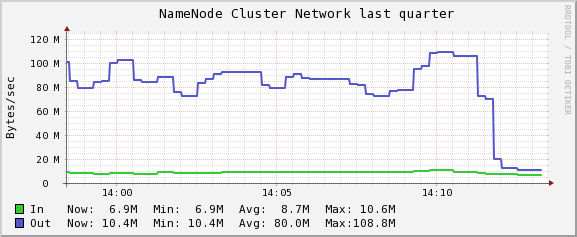
14:00停掉RaidNode,但Raid job继续运行的情况下,发现namenode的网络流量并没有变化,仍然居高不下。而当杀掉正在运行的3个Raid job以后,namenode流量立刻有一个大幅度的下降。由此可以推测流量上涨和Raid Job有关。
进一步观察异常时期Raid Job的作业发现,流量上涨时,正在raid的文件中有大量blocksize=1M的文件。怀网络流量暴涨与blockSize较小的文件进行raid有关。仔细分析代码有如下几点值得注意:
-
文件大小一般都是几百M,这意味着一个文件blockSize大概在几百个左右。而Raid job在进行raid时或通过srcFs.getFileBlockLocations(stat, 0, stat.getLen());获取整个文件所有的block数据校验是否符合进行。以文件有200个block计算,该调用1次返回接近30k左右。
-
Encoder在对源文件进行raid 编码时会同时打开10个InputStream(详见Encoder.stripeInputs()),打开过程先open,然后seek到响应偏移量,HDFS的open操作会预先读取一定大小的数据对应block的信息,该大小默认是10xdefaultBlockSize,其中defaultBlockSize在RaidNode中是256M,这意味这一次open将预先读取2560M数据,这对于blockSize=1M的小文件,这将返回2560个block的信息(实际返回是2560和文件block总数中较小的)。
-
RaidNode中PurgeMontior线程会每隔10s对raid的文件进行检查清理,并通过PlacementMonitor来校验是否有parity block和src block放置重复问题,PlacementMonitor同样会查询文件的所有block信息。
以上三个地方在文件的block数较大时均会从NN获取较高的数据,为此,我做了一个测试:
- 构建200个文件大小为200M,blockSize为1M的文件,对这个文件目录进行raid
- 关掉RaidNode
- 构建200个文件大小为200M,blockSize为32M的文件,对这些文件目录进行raid
- 重复1.
得到NN的网络流量结果如下:

- 流量第一次增长是在200个blockSize=1M的文件进行raid
- raid job完成后,流量基本保持在一个新的高位。
- 随后关掉raidNode,流量降至为0.
- 重启raidnode之后,流量恢复至之前水平,并出现一个短暂的高峰。
- 随后进行blockSize=32M的文件raid,流量未见明显增长。
- 最后进行新的200个blockSize=1M的文件raid,流量上升到一个高峰后,在job运行完,流量有所回落,但比job运行前的流量略高。
基本可以验证大量block数过大的文件的raid将导致NN流量上涨。
再次修复
上述问题中第2点是网络消耗最大,且最容易修复,只需要在Encoder之前设置RaidJob的dfs.read.prefetch.size为10x源文件blockSize,而不是默认的使用defaultBlockSize即可避免预读过大的问题。
重新验证
修改后进行了测试,通过对20个大小为200M,blockSize=1M的文件进行raid,在raid job运行时,NN的网络情况对比如下图所示:
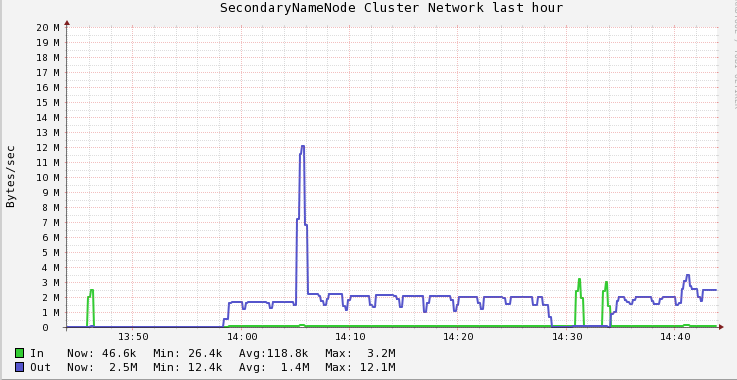
14:05的峰值为修改前版本的raid job运行时NN out流量峰值,12M/s左右 14:41的峰值为修改后的版本,峰值为3.5M/s左右. 至此,问题基本解决
blog comments powered by Disqus